At the moment, everything is focused on super intelligent applications that can process and understand texts and answer questions about them. And LangChain is one of the most popular developer platforms for this! LangChain connects AI models, such as OpenAI’s Chatgpt, with all kinds of data sources (e.g. local/cloud stored database) so that you can provide a totally customized Natural Language Processing (NLP) solution according to your own needs.
However, the open-source framework so far only works in connection with Python and JavaScript. Fortunately, we can use the reticulate package to build a bridge to Python and build an NLP solution with only some plain basic Python code.
1 Our Use Case
Things are getting busy again in the financial sector at the turn of the year. Portfolios are polished up for the end of the year results and from small to major analyst firms begin their forecasts for the coming year. However, this means that there are dozens of analyses with countless pages to read: example list of latest 2024 market forecasts documents
Now, to go through all of these will take A LOT of time and some content will overlap and become redundant. Therefore, it would be beneficial to be able to easily and conveniently ask your own NLP solution to the content of your reading. Therefore, instead of reading every single document, we prefer to ask specific questions and let the AI model gives us the answers!

2 Prepare Environment
2.1 API Connection
First, of course, we need a connection to OpenAI and setup an API account:
https://openai.com/product
Now, as we have set up an account and received the api key, we save it in an external .txt file on the hard disk. From there, we can use the rgpt package to load the key into the R environment, if required.
rgpt3::gpt3_authenticate("~/api_access_key.txt")As a further precondition to be able to run the subsequent python scripts in the R environment,
we need to ensure to have the reticulate package installed.
install.packages("reticulate")Obiously, if you don’t already have Python installed, download a version from the website at python.org.
Here, we also used the reticulate package to install the latest Version of 3.10
reticulate::install_python("3.10:latest")To test if the installation has been successful, we can simply run a test like:
reticulate::py_run_string('print("Python is setup and running!")')2.2 Initial Python setup
After Python has been properly installed, we create a virtual environment in which we load all the necessary packages for our project. Like in R projects, we need only to load the packages once !
As we are referring to a langchain project, we name the environment “langchain_env” and load the necessary packages:
reticulate::virtualenv_create(envname = "langchain_env", # name environment
packages = c("langchain","unstructured","openai","python-dotenv","pypdf","chromadb","bs4","tiktoken") # load initial packages
) In case you need to install further packages after creating the environment, you can simply use py_install()
reticulate::py_install(packages = c("numpy"), envname = "langchain_env")2.3 Project’s common entry point
After the initial setup, this is the entry point for reopening the project. Here, we reactivate our virtual environment and load the API key into R.
reticulate::use_virtualenv("langchain_env")
rgpt3::gpt3_authenticate("~/api_access_key.txt")Since we will need the API key in the Python code, we need to convert it once from the r object to a Python object.
py_api_key <- reticulate::r_to_py(api_access_key)
3 Prepare Market Document
3.1 Text splitting
Before we can ask Chatgpt questions about our market documents, we first have some preparation and preliminary work to do:
As the next step, we create a folder to store our PDFs, like “gpt_doc” and save the path in the following Python script.
For a better traceability of the individual steps and breakdowns, we read in the 1 document “goldmansachs_credit_outlook_24.pdf” for further processing.
Via langchain we import the document and check the number of pages loaded in:
reticulate::py_run_string('from langchain.document_loaders import PyPDFDirectoryLoader
pdf_loader = PyPDFDirectoryLoader("~/gpt_doc/")
all_pages = pdf_loader.load()')Another great convenience of the reticulate package is that we can use the Python objects such as ‘all_pages’ directly in R. This means that we can either throw a ‘print’ message directly in the Python code or conveniently analyze temporary results in R.

We now have to break the text down into smaller blocks to enable Chatgpt later on to find matching content and return it to us.
Using langchains' split_document we see the 25 pages are split up into 29 blocks:
reticulate::py_run_string('from langchain.text_splitter import RecursiveCharacterTextSplitter
splitted_doc = RecursiveCharacterTextSplitter().split_documents(all_pages)')The more blocks the text is split into, the more granular the search. But if the text section is too small, the more confusing the answer will be. So we ought to define an appropriate block size here, which we can specify as the border size in the Python code. We have therefore increased the number of blocks from 29 to 97 with a maximum size of 900.
reticulate::py_run_string('chunk_size = 900
chunk_overlap = 150
from langchain.text_splitter import CharacterTextSplitter
new_splitted_doc = CharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap, separator=" ").split_documents(all_pages)')
Let’s take a quick look at the 97 blocks as an interim result and see if the output meets our expectations.
py$new_splitted_doc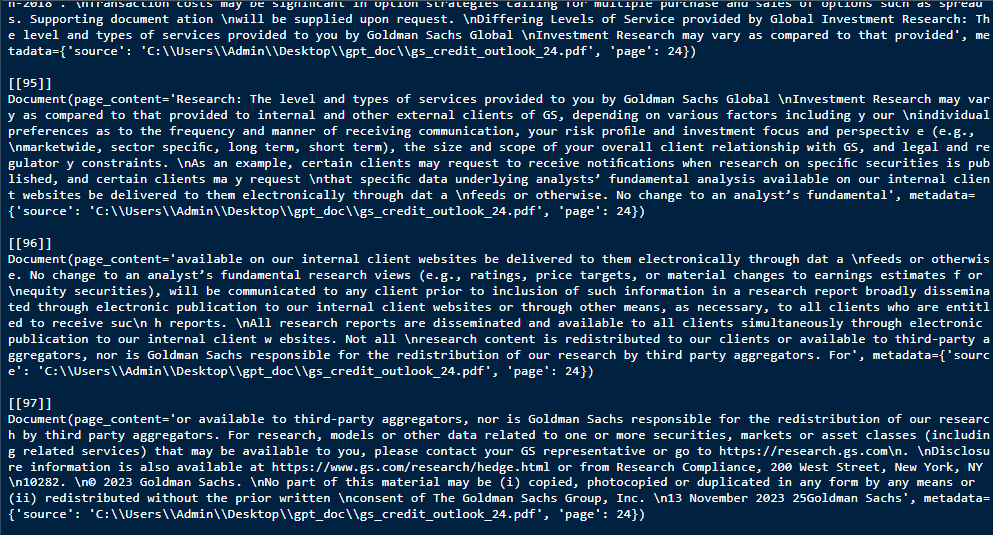
3.2 Check Chatgpt costs
If we now want to upload the blocks to Chatgpt in order to receive the answers to our questions, we should first check what costs we will have to expect. In order to do this, we need to know the total number of tokens from our research document. In this case, we can use the OpenAIR package, which uses the following purrr::map function to sum up the tokens of all 97 blocks, which is in total 15027.
purrr::map_int(py$new_splitted_doc, ~ TheOpenAIR::count_tokens(.x$page_content)) |>
sum()
The cost of our research with $0.0001 per 1K tokens is at roughly: 15027/1000 * 0.0001 = $0.0015
So - good to go …
4 Connect Vector DataBase to OpenAI
Now that we have loaded and prepared the text, we can move on to the actual technical preparation. We need to create word embeddings and a vector database to store all the information, for which there are several approaches possible.
But first, one step back. Basically, word embeddings are used to represent words as vectors in a low-dimensional space and then measure a relationship between text strings. These embeddings capture the meaning and relationships between words, on which machine learning models can base natural language and better understand and process the texts. Chatgpt and other large language models (LLMs) rely heavily on it.
Moreover, we need a vector database in which we can save our work. Chroma is an AI-native open source vector database that can be integrated directly into common LLMs. A big advantage with Chroma is that we can save a local instance. What we can do now, in general, is to easily calculate and save embeddings and then efficiently search for data with similar embeddings.
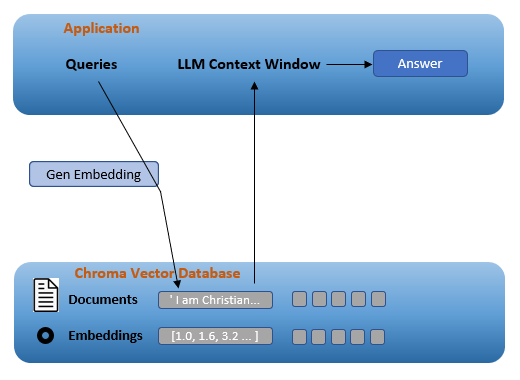
Link to further explanation: python.langchain.com
4.1 Setup Vector Database
To be able to save the embeddings, we can use Chroma’s local storage service and save everything in a newly created folder.
reticulate::py_run_string('import os
from langchain.embeddings.openai import OpenAIEmbeddings
os.environ["OPENAI_API_KEY"] = r.py_api_key
embedding_obj = OpenAIEmbeddings()
from langchain.vectorstores import Chroma
# Place to store Eemdeddings
chroma_store_directory = "~/gpt_chroma_db"
# Setup Vector Database
vectordb = Chroma.from_documents(
documents=new_splitted_doc,
embedding=embedding_obj,
persist_directory=chroma_store_directory)')4.2 Setup OpenAI Connection
in our use case, we use Chatgpt’s LLM gpt-3.5-turbo model and link this to our vector database. The result is a Q&A concatenation that we can use for our questions.
reticulate::py_run_string('import openai
from langchain.chat_models import ChatOpenAI
# Assign Chatgpt model
llm_model = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Using langchains RetrievalQA to create a Q&A chain
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm_model,retriever=vectordb.as_retriever())')
5 Now Ask Your Questions
To easily and conveniently ask our questions about the goldmansachs_credit_outlook_24 text, we can use the following code, which retrieves the answers in the background via our created Q&A chain.
py_run_string('
print(qa_chain.run("What happens beginning 2024?"))
')
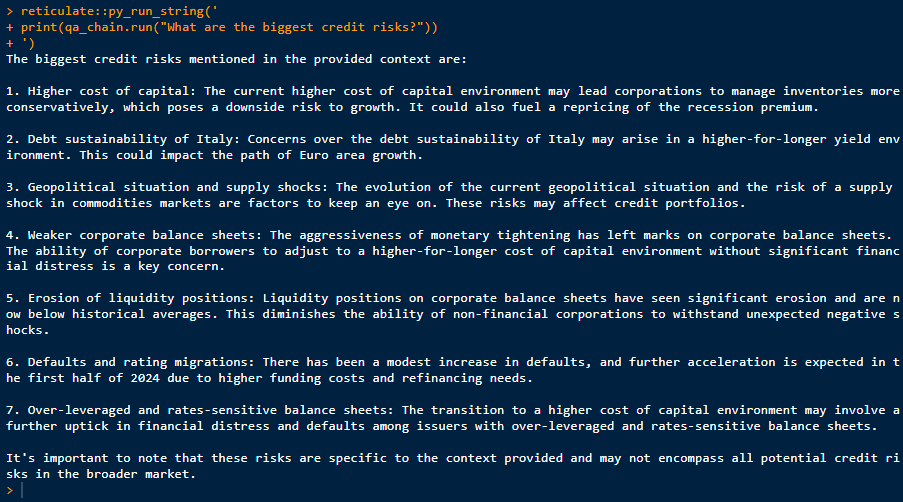
As our example is a credit market analysis from Goldmann Sachs for the coming year 2024, we also would like to know what the greatest possible credit risks could be in 2024?.
py_run_string('
print(qa_chain.run("What are the biggest credit risks?"))
')
Now that we know the biggest risks, we obviously also want to know the biggest investment opportunities for 2024, which is discussed in the document.
reticulate::py_run_string('
print(qa_chain.run("What are the biggest investment opportunities?"))
')
Of course, we can now ask countless other questions. But it makes more sense for a holistic market overview, if instead of uploading 1 document, as we have done here in our use case study, we now upload several documents on market expectations 2024. Instead of having to read them all individually, the answers come directly from our q&a_chain!
6 Professional Implementation Option
Many good supporting methodologies are not used to full effectiveness by individuals and organizations. This is often due to inadequate planning and inadequate consideration of the opportunities that the methodology creates.
A first simple approach comes with the advantage of the R environment. Thanks to the Shiny package, an easy-to-use user interface can be created so that no further programming knowledge is required. Here, documents can be selected and uploaded and the answers to the questions can be displayed in a dialog screen - at the push of a button.
Examples of such Shiny applications already up and running can be seen with our Market Dashboard and Stock Price Estimations Apps.
Finally, having reached this point, thank you for your interest - really appreciated! And please provide your feedback and get in touch for further discussions and examples! via
Looking forward to!